شركة IBM تطلق أداة مفتوحة المصدر لتحويل أي مستند إلى بيانات قابلة للمعالجة!
2026/03/07
عاجل: شركة IBM تطلق أداة مفتوحة المصدر لتحويل أي مستند إلى بيانات قابلة للمعالجة!
أعلنت IBM عن إطلاق مكتبة Python مجانية ومفتوحة المصدر تُسمّى Docling، صُمّمت خصيصًا لتحويل المستندات غير المنظمة (مثل ملفات PDF، DOCX، PPTX وغير ذلك) إلى بيانات منظمة قابلة للاستخدام والتحليل. (http://docling.ai)
ماذا تفعل Docling؟
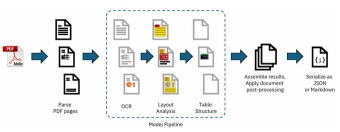
•تقرأ ملفات المستندات المختلفة وتحوّلها إلى بيانات منظمة (مثل JSON أو Markdown) بدلاً من مجرد نص خام. (http://docling.ai)
•تميز بين عناصر الوثيقة مثل العناوين، الفقرات، الجداول، القوائم، الصيغ الرياضية، والرموز البرمجية وتحتفظ بهيكلها الأصلي. (http://docling.ai)
•يمكنها التعرف على ترتيب القراءة داخل الصفحة، أي أنها لا تكتفي بقراءة النص فقط وإنما تفهم كيف تم ترتيب المحتوى داخل المستند. (http://docling.ai)
•تستطيع استخراج الصور وتسمية محتواها، وتربط العناوين بالعناصر ذات الصلة مثل الجداول أو الرسوم. (http://docling.ai)
كيف تستخدمها؟ يمكن تثبيتها كحزمة Python باستخدام:
pip install docling
ثم تستخدمها لتحويل المستندات في تطبيقات Python أو من واجهة سطر الأوامر بكل سهولة. (http://docling.ai)
لماذا هي مهمة؟ عادةً، أدوات قراءة المستندات (OCR التقليدية) تقتصر على استخراج النص فقط، وغالبًا ما تضعف في التعامل مع الجداول أو تنسيق المستندات المعقدة. Docling لا تكتفي بهذا فحسب، بل تحافظ على الهيكل الكامل للمستند، مما يجعلها مثالية لاستخدامها في تطبيقات الذكاء الاصطناعي مثل توليد الإجابات المعززة باسترجاع المعلومات (RAG)، أو تدريب نماذج ذكاء اصطناعي على بيانات موثوقة. (IBM)